
Analytics can be complicated when it comes to enterprise landscapes. When you need to handle a high volume of data in a complex app ecosystem. Add to that that multiple users will be consuming data, and it is necessary to implement a robust data staging mechanism.
Tools like Microsoft SQL Server Integration Services (MS SSIS), AWS Glue, Azure Data Factory, provide different approaches to data ingestion automation, capable of handling large data sets with enterprise-grade performance and security. However, to include your OutSystems data in your analytics processes you need to use Hubway Connect.
We will walk you through how to build an enterprise-grade data pipeline, sourcing OutSystems apps’ data using Hubway Connect OData APIs in an ETL process and how to leverage MS SSIS for extraction and loading. From fundamental 1-to-1 table replication to complex incremental data synchronisation logic.
We are using MS SSIS for the context of this article; however, Hubway Connect will work seamlessly with any enterprise data tool, either standalone or in the cloud.
Hubway sourcing in action
To demonstrate this enterprise-grade data pipeline solution, we built a PoC (Proof of Concept) that uses Hubway Connect in an enterprise-scale scenario where data is staged in an SQL Server Database to be used for reporting.

For this purpose, MS SSIS has been used as the ETL tool. Hubway Connect exposes OutSystems app data via OData APIs. MS SSIS connects to the Hubway OData service, extracts the data, and loads it into a staging area based on a SQL Server Database.
In this step-by-step guide:
- We will set up an MS SSIS environment in the MS Azure Cloud.
- We will connect to Hubway’s OData services to fetch and load data into a SQL server staging table.
- An incremental sync logic will be implemented to reduce the data amount involved in the loading.
- How Hubway deals with the MS SSIS x OData v4 data type conversion problem.
- A performance benchmark across different cloud resourcing setups and MS SSIS configuration aspects.
- We will review some best practices to guarantee good performance when handling with large data loads.
Setting up MS SSIS Integration Runtime on MS Azure
Resources Required:
For this exercise, you will need an Azure Subscription, Azure Resource Group, Azure SQL Server, Azure SQL Server Database, and Azure Data Factory V2.
Required Software:
| Software | Details |
| Microsoft Visual Studio 2019 with MS SSIS installation package or MS SSIS Tool (for earlier versions). | Install Microsoft Visual Studio 2019, and during the installation, select Data storage and processing. Then go to the extensions tab. Select integration services and download (or get the extension directly from here). |
| SSMS – Sequel Server Management Studio
or Azure Data Studio. |
To view/query data on the SQL Server Database. |
Set up a SQL Azure Server and create a Database.
Next, create an Azure MS SSIS Integration Runtime in ADF.
Sourcing data from Hubway Connect’s OData APIs
Let’s consider that we have a Person Entity in a Sample OutSystems Application, and this Entity contains the details of a person like a name, email and address.
Launch the Hubway Builder and create a New Project.
Enter a project name in the New Project Name field. The service name will be auto-generated, and you can modify the service name if required.
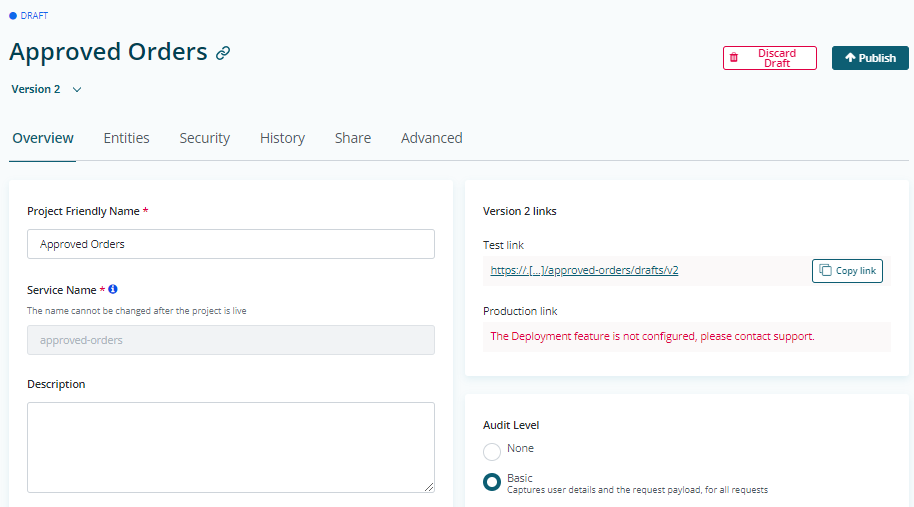
Navigate to the Entities tab of the Project. Search for Person and add the Entity.
In this demo, you can leave the Security settings as default and allow the service to be accessible to any valid user account.
Click the Publish button. This will generate the service link.
How to create a replica database and export data
Create an MS SSIS Project, add an OData Source that will connect to Hubway Service and extract data. Next, add an OLEDB Connection to the Azure SQL Database to write data into the destination table within SQL Database.
Creating an MS SSIS Project in Visual Studio using MS SSIS IR (Integration Runtime) in Azure
- Login to Visual Studio with the account with access to the Azure Data Factory/MS SSIS IR.
- Select the template “Integration Services Project (Azure-Enabled).
- Connect to Azure Data Factory.

- Select “Select MS SSIS IR in ADF” (Once logged in, the Azure subscription information will be automatically populated). Select the data factory and the integration runtime from the previous steps.



Create an MS SSIS Project in Visual Studio using MS SSIS IR (Integration Runtime) in Azure
- Add a Data Flow Task.

- Add an OData Source.

- Copy the Test Link from the Hubway Connect project.

- Paste the link from the previous step to the Service document location. Select Basic Authentication and set the credentials (username and password) of a user with access to the Hubway Connect project.
- Test the connection.

- Select Person Entity in the OData Source Editor and Preview the data.
- Add an OLE DB Destination to the DataFlow Task and connect the ODataSource.

- Open the OLE DB Destination and create a new Connection Manager.
- Create a new “Data Connection”.
- Select the provider (SQL Server Native Client), and enter the Azure server name. Select SQL Server Authentication and enter the credentials defined previously. Then select the Database created previously. Test the connection.
- In the Connection Manager, select “New” to create a new table. A script will be generated automatically to create a table with the same columns as the ones made available through the OData source. Click OK, and a new table will be created.







If you already have a destination table in Azure SQL Database, you can use that. Note: the destination table should have the same attributes and data types as the OData source Entity.
- Go to mappings and make sure all columns are mapped from the source (OData) to the Destination (SQL Server).

- Execute the package in Azure.
- This will connect to Hubway service, fetch the data from Person Entity and load it into the destination table in Azure SQL Database.
- You can verify the execution by connecting to the SQL Server and doing a select query on the destination table.



Handling OData Date and Time fields in MS SSIS
MS SSIS does not recognise ‘Date’ or ‘Time’ type fields from an OData v4 source. To overcome this issue, Hubway has a feature that converts Date or Time types to DateTime type.
In the example below, OutSystems has an Entity called Person20k with a DateOfBirth field of type Date.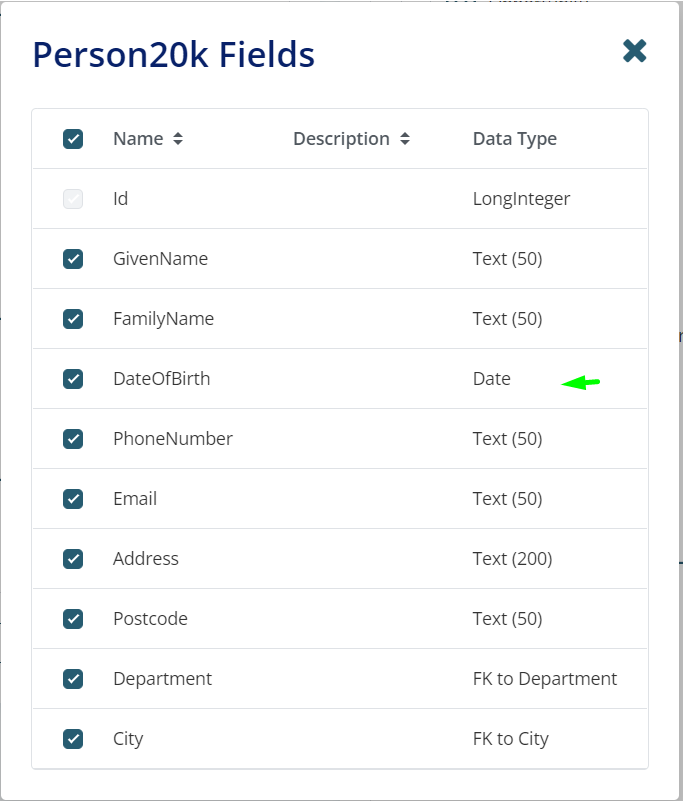
When you use an OData source in MS SSIS to get data from this table, you may run into the following error.
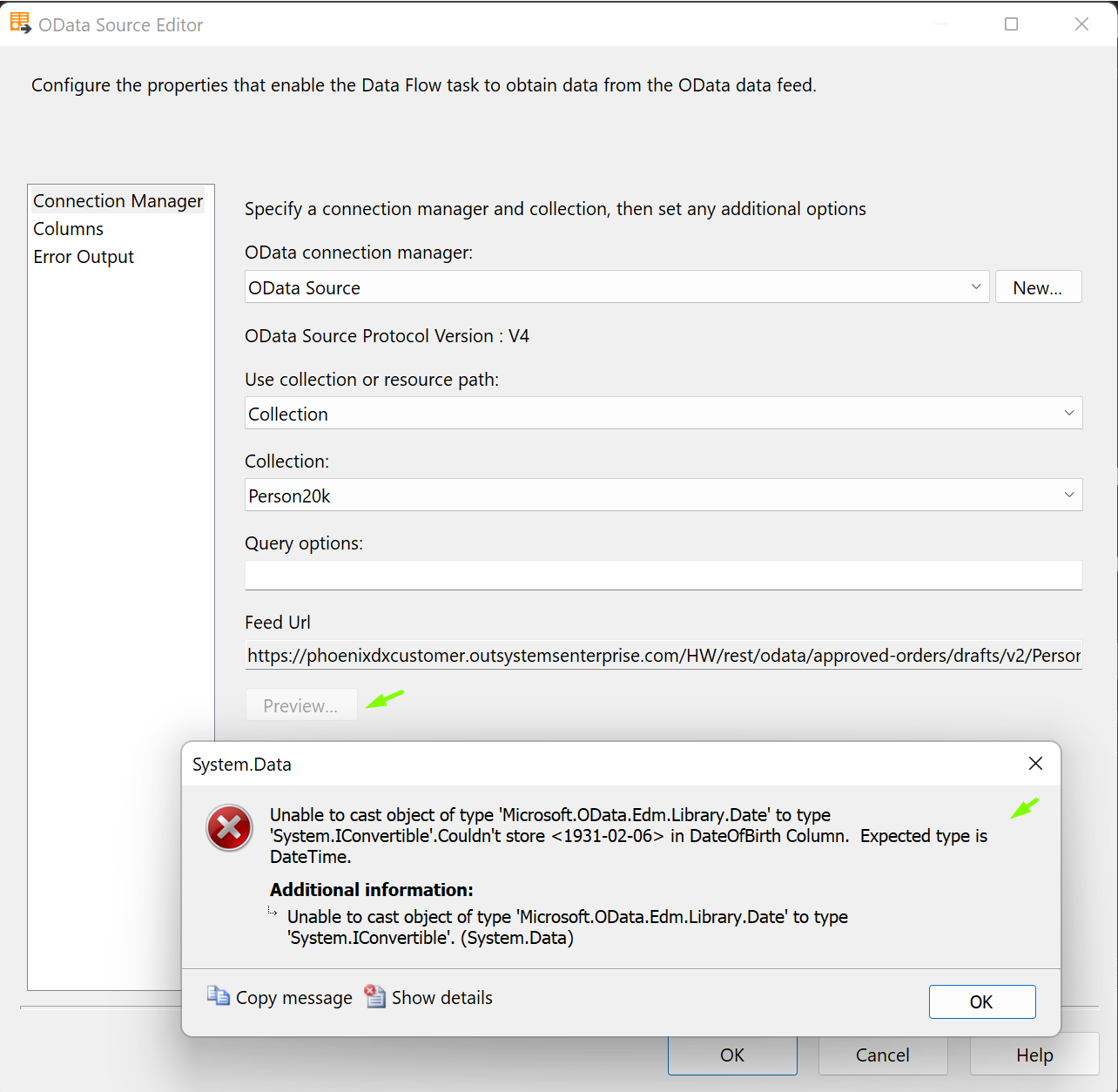
Hubway solves this problem with its “Cast Date and Time attributes as DateTime” feature.
Go to your Hubway Project → Project → Advanced Settings.
Turn on Cast Date to DateTime toggle on Hubway’s project to workaround the MS SSIS date conversion issue.
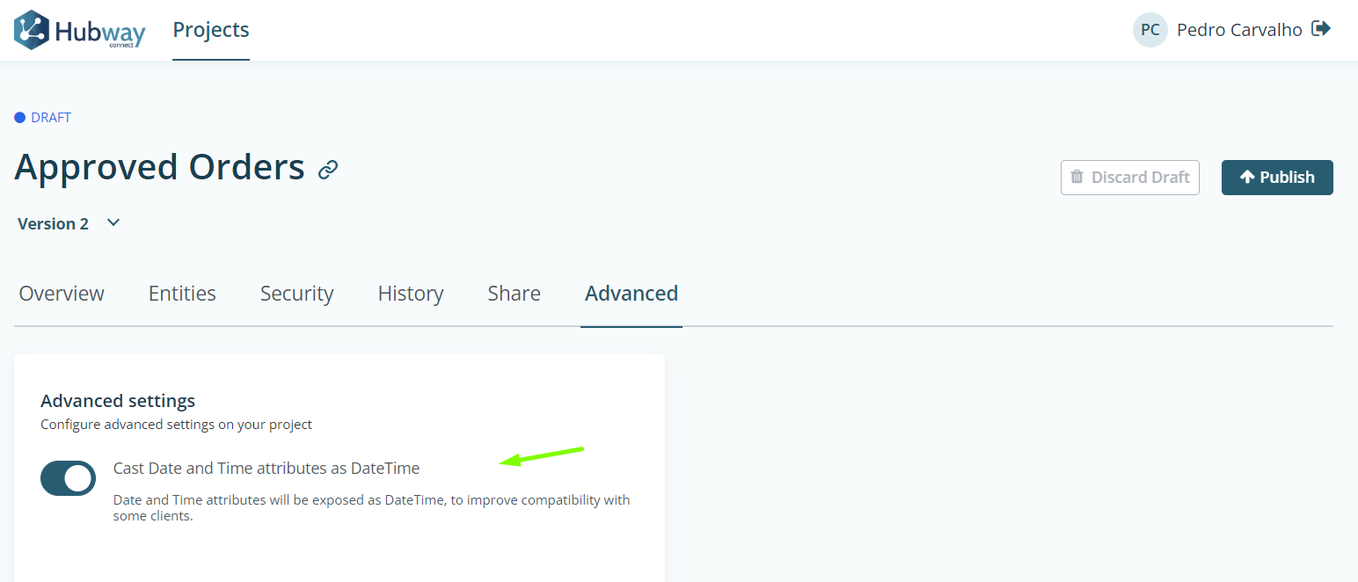
If you go back to the Person table you can now see that the Date is now being cast as DateTime. Refer to Hubway FAQ Cast Date and Time Attribute as DateTime for more details on this feature.
You can now convert it back to Date type within MS SSIS by adding a Data Conversion task.
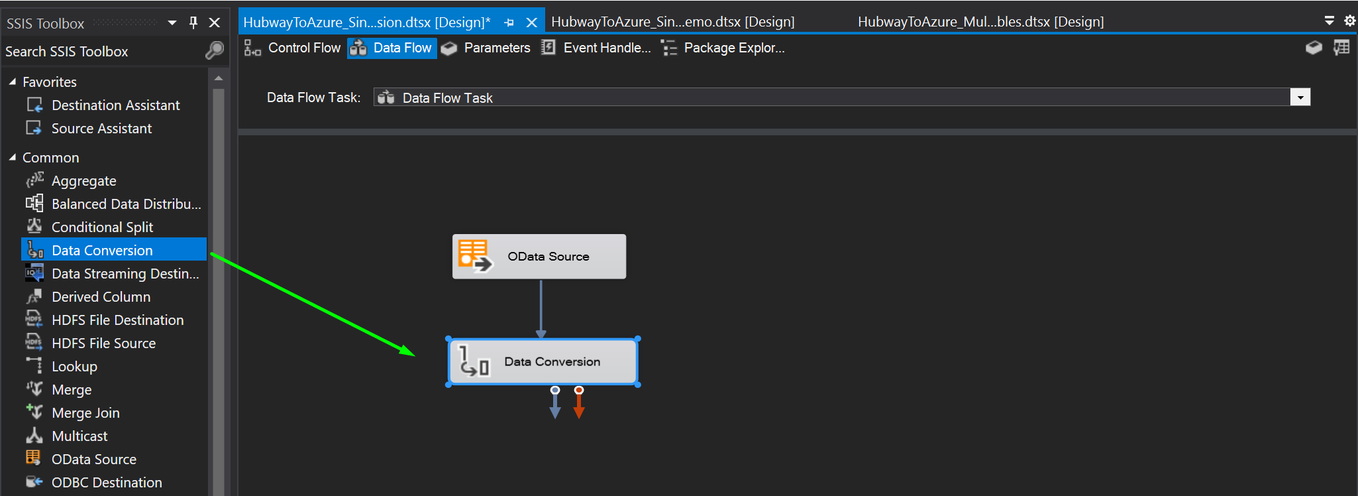
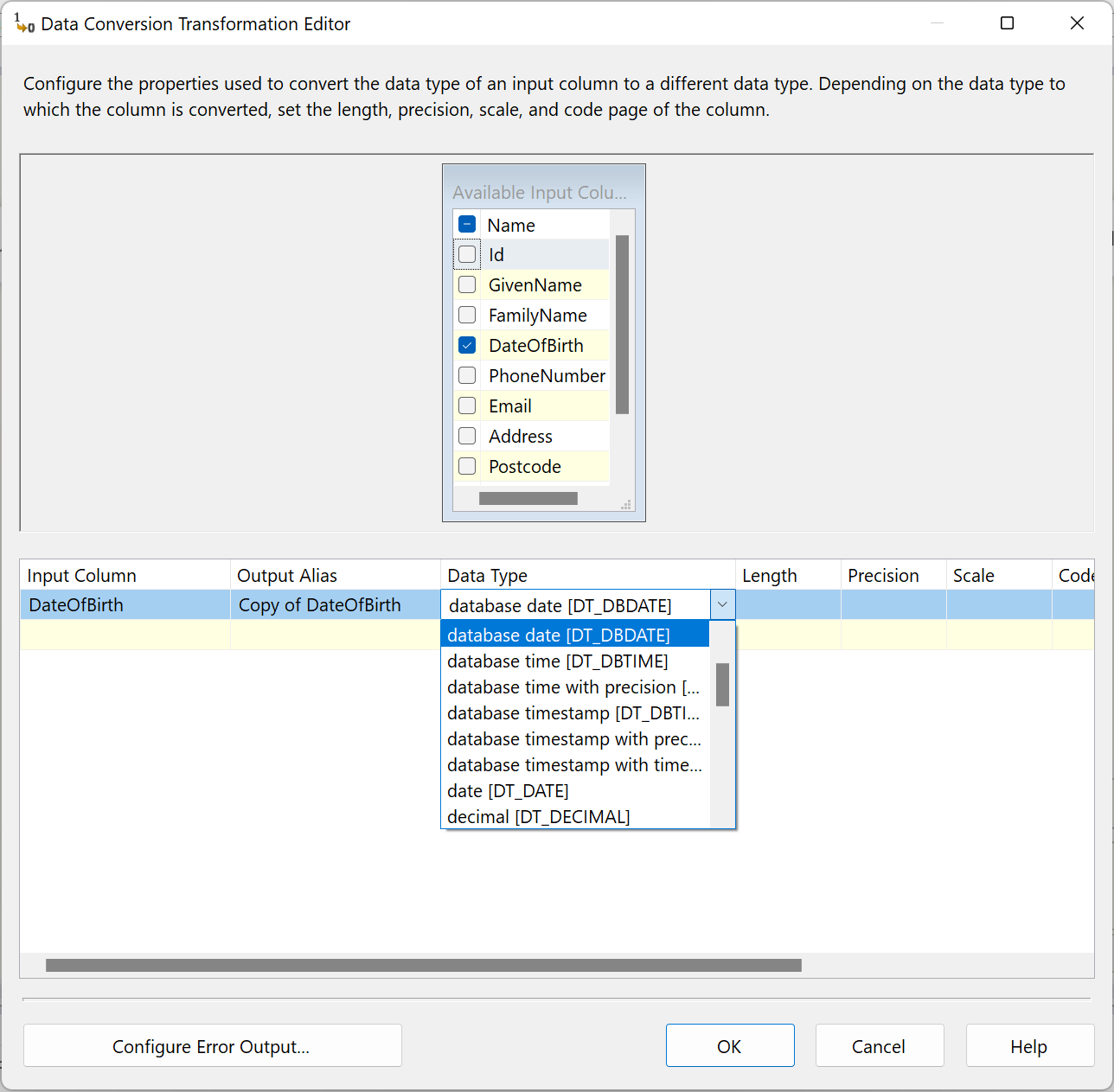
This will convert the datetime field back to Date field. You can then load it into a new column in the destination table.
Go big with data – Handling Incremental loads
Enterprise systems have large volumes of transactional data that necessitate ETL systems to look for changes daily and insert/update them into the staging tables.
Hubway provides a simple and more straightforward approach to incremental loading with MS SSIS.
The incremental load pattern involves performing multiple “incremental” syncs. When executing each synchronisation, we will fetch only those records from the source system that have been created or modified since the previous synchronisation up until the moment we have started the current execution.
Below is a visual representation of the incremental data load using MS SSIS:
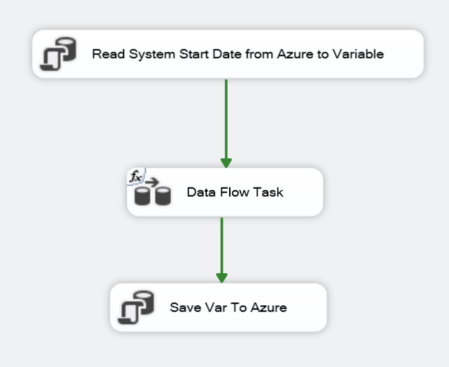
Steps to achieve incremental load:
- Read the date and time of the previous execution:
- In the MS SSIS project, create a variable named LastSync (@[User::LastSync]) to keep the value of the LastSync date time. Initially, this variable will be null.
- MS SSIS also has a system variable @[System::StartTime] that holds the date time of the start of the execution of our package. This variable will be used in the next step.
- Incremental data load:
- On the OData Source query options, you can create a dynamic expression using the above-mentioned variables to fetch the Orders that were created or updated since the last sync.
$filter=UpdatedOn ge @[User::LastSync] and UpdatedOn lt @[System::StartTime]
If you now go into the OData source Editor you will see that the Query options fields have been automatically populated with the result of the expression that we defined above (using the variables values in Design time).
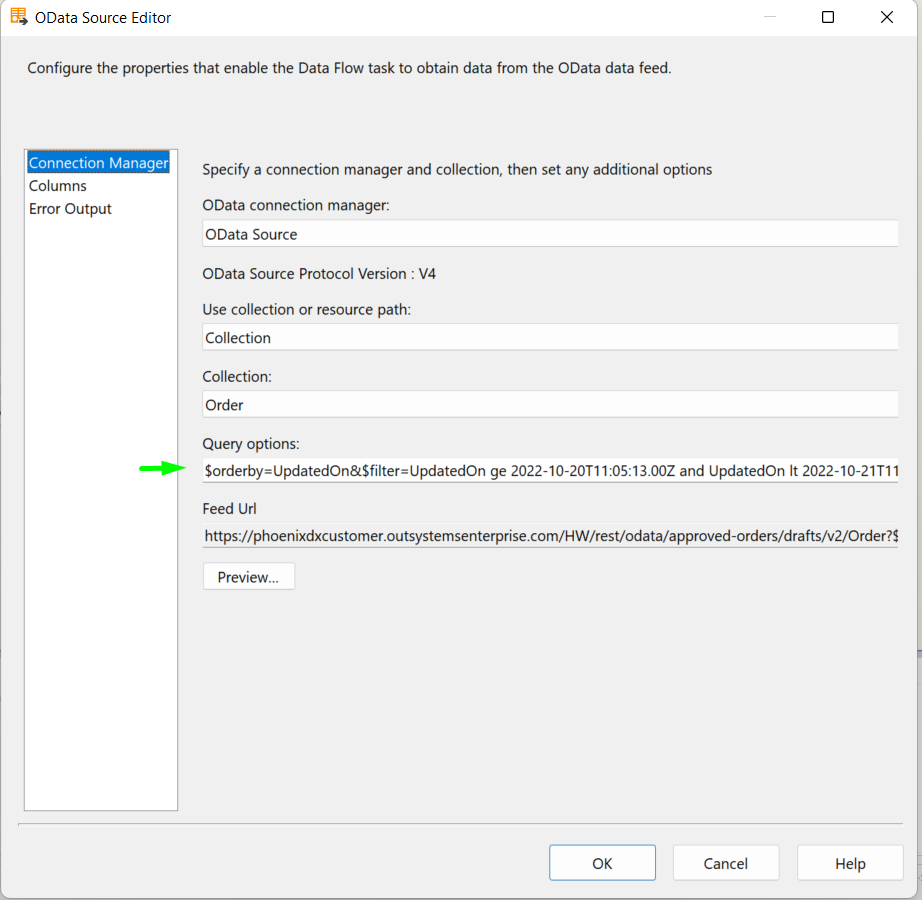
When executing the package, the expression will be evaluated with the runtime values of the variables.
- Use a Lookup node in MS SSIS that will iterate through each record obtained from the source through the query above. If a matching record already exists on the destination table in Azure, then update the record. If there is no match, then Azure will create a new record on the destination table.

- Update the value of the (@[User::LastSync]) variable and save it to an Azure table or file. This will be used in the next execution cycle.

Accordingly, we see that Hubway’s OData service offers a standard approach that facilitates any enterprise ETL tool to filter and load incremental data.
Performance benchmarking
Hubway Connect research team conducted experimental iterations on MS SSIS data load with different Azure configurations. We present the configurations that had notable improvements to the data load performance.
| Iteration | 1 | 2 | 3 |
| Description | Basic Computing power with default Buffer settings without Fast Load | High Computing power with default Buffer settings with Fast Load and AutoAdjustBufferSize | High Computing power with default Buffer settings with Fast Load and AutoAdjustBufferSize with 500 buffer max rows |
| Server Computing | min of 0.5 up to 1 (max) Vcores | min of 2.5 up to 4 (max) Vcores | min of 2.5 up to 4 (max) Vcores |
| Server Memory | min of 2.02Gb up to (max) 3Gb | min of 7.5 Gb up to (max) 12 Gb | min of 7.5 Gb up to (max) 12 Gb |
| AutoAdjustBufferSize | False | True | True |
| DefaultBufferMaxRows | 10,000 | 10,000 | 500 |
| DefaultBufferMaxSize | Blank | Calculated automatically | Calculated automatically |
| OLE DB Destination “Data Access mode” | Table or View (no Fast Load) | Fast Load | Fast Load |
| Load time for 1M records | 01:30:14.110 | 00:18:58.232 | 00:03:03.218 |
As we can observe from the results above, significant improvements were verified with:
- Setting the OLE DB Destination “Data Access mode” to Fast Load resulted in a reduction of 20% load time when compared to “no Fast Load”.
- Setting the AutoAdjustBufferSize to true together with the reduction of the DefaultBufferMaxRows: contributed to a 14% reduction in time compared to the default values of BufferMaxRows (10,000) and Buffer size of 10Mb.
- Increasing computing power alone does not yield a significant performance increase compared to the two factors mentioned above.
Therefore it is recommended to always:
- Set the OLE DB Destination “Data Access mode” to Table or View – Fast Load.
- Set the AutoAdjustBufferSize to true, and then progressively adjust the BufferMaxRows to find the optimum value of increased performance.
Different organisations may prefer varying approaches to address performance optimisation, as servers may be shared by multiple applications and price-lines may differ.
In Conclusion
By adhering to OData standards, Hubway acts as a standard API gateway to OutSystems data, serving as a data hub and opening pathways to large scales of data staging and consumption. Incremental data loading is a fundamental resource to be applied to enterprise data pipelines, as it is the best way to prevent the impact on applications in runtime.
We also observed that a few key MS SSIS settings can significantly affect processing time when handling large amounts of data, reducing the time it took to process 1 Million records from 1.5 hours down to 3 minutes by tweaking some configurations.
Modern data pipeline implementations in the OutSystems ecosystem can now leverage a no-code API Builder, Hubway Connect, to make transporting data into a staging DB much simpler and more robust.